
jgreco
Resident Grinch
- Joined
- May 29, 2011
- Messages
- 18,680
ZFS is a complicated, powerful system. Unfortunately, it isn't actually magic, and there's a lot of opportunity for disappointment if you don't understand what's going on.
RAIDZ (including Z2, Z3) is good for storing large sequential files. ZFS will allocate long, contiguous stretches of disk for large blocks of data, compressing them, and storing the parity in an efficient manner. RAIDZ makes very good use of the raw disk space available when you are using it in this fashion. However, RAIDZ is not good at storing small blocks of data. To illustrate what I mean, consider the case where you wish to store an 8K block of data on RAIDZ3. In order to store that, you store the 8K data block, then three additional parity blocks... not efficient. Further, from an IOPS perspective, a RAIDZ vdev tends to exhibit the IOPS behaviour of a single component disk (and the slowest one, at that).
So we see a lot of people coming into the forums trying to store VM data on their 12 disk wide RAIDZ2 and wonder why their 12 disk 30 TB array sucks for performance. It's exhibiting the speed of a single disk.
The solution to this is mirrors. Mirrors aren't as good at making good use of the raw disk space (because you only end up with 1/2 or 1/3 the space), but in return for the greater resource commitment, you get much better performance. First, mirrors do not consume a variable amount of space for parity. Second, you're likely to have more vdevs. That 12 drive system we were just talking about will have 4 three-way mirrors or 6 two-way mirrors, which is 4x or 6x the number of vdevs. This translates directly to greatly enhanced performance!
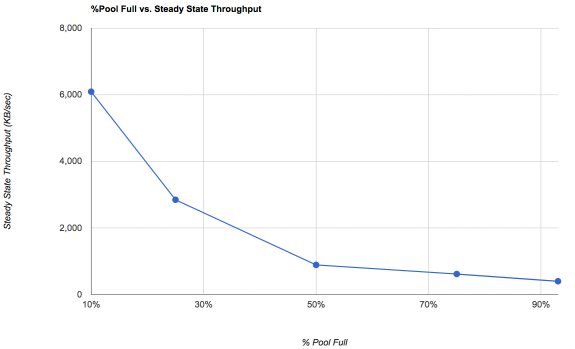
Another substantial performance enhancement with ZFS is to maintain low pool occupancy rates.
For RAIDZ style file storage, it's commonly thought that performance will suffer once you pass the 80% mark, but this isn't quite right. It's a combination of fragmentation and occupancy that causes performance to suffer.
For mirrors, this is also true, but because the data being stored is often VM disk files or database files, it becomes more complicated. Because it is a copy-on-write filesystem, rewriting a block in a VM disk file causes a new block somewhere else to be allocated, and creates a hole where the old block was, when that block is freed (after any snapshots are released, etc). When writing new data, ZFS likes to allocate contiguous regions of disk to write its transaction groups. An interesting side effect of this is that if you are rewriting VM disk blocks 1, 5000, 22222, and 876543, these may actually be written as sequentially allocated blocks when ZFS dumps that transaction group to disk. A normal disk array would have to do four seeks to do those writes, but ZFS *may* be able to write them sequentially. Taken to its logical conclusion, when ZFS has massive amounts of free space available to work with, it can potentially be five or ten times faster at performing writes than a conventional disk array. The downside? ZFS will suffer if it lacks that free space.
If you want really fast VM writes, keep your occupancy rates low. As low as 10-25% if possible. Going past 50% may eventually lead to very poor performance as fragmentation grows with age and rewrites.
A discussion of how ZFS RAIDZ space allocation often chews up more space than you are expecting.
You shouldn't be using RAIDZ with block storage at all, because RAIDZ uses a variable amount of parity to protect your data depending on the block size, and this can cause excessive waste. It is totally possible to engineer a situation where your parity uses several times as much space as the data it is protecting. Performance will slowly degrade over time if your pool is more than 50% full, as well.
https://extranet.www.sol.net/files/freenas/fragmentation/delphix-small.png
[from a discussion where the poster had an 8-wide RAIDZ2] Because you've got an 8-wide Z2, your optimal block size is six drives wide.

https://extranet.www.sol.net/files/freenas/fragmentation/RAIDZ-small.png
The only case where allocation happens optimally is where you have a block size of 6 * your sector size, or some multiple thereof. So if your ashift=9, then that's a 3072 byte block, or if ashift=12, then 24576 bytes. These are not natural sizes. You only get the natural sizes if you follow the old power rules for the number of disks in a pool (RAIDZ2 = 6 or 10 disks, etc).
So then as an example of how this goes awry, if your ashift=9 and you have a zvol volblocksize of 4K, you need to allocate an (optimal) 3072 byte block on eight sectors, but then you have a leftover of two 512-byte sectors, which needs to be protected by parity, so that's three sectors, but ZFS won't allocate odd numbers, so that's four sectors, so you're using twelve total sectors to write that 4K block, or 50% overhead. If your ashift=9 and a zvol of 8K, that's two optimal blocks on sixteen sectors with a leftover of four 512-byte sectors, plus parity/pad, six more sectors, so that's twenty two sectors to write that 8K block, or 38% overhead.
But it all goes to total heck with ashift=12 (4K sectors). The most obvious one is where you have a 4K zvol volblocksize and you store a 4K block. You need a 4K parity to protect that, so you're instantly at 100% overhead. If you do that on RAIDZ3, then you actually need 3 * 4K parity to protect it, so 300% overhead. So you go to larger volblocksize. So the 8K zvol volblocksize seems like it might work out better, but in reality you need two sectors for data, one for parity, and then one for pad, so you're still at the 100% overhead. You actually have to get up into larger volblocksizes and design them in concert with your pool in order to have a chance at a more optimal configuration. As you raise the volblocksize, you will approach a more optimal situation, but not actually reach it.
But even then, this is sort of screwed up because with the introduction of ZFS compression, things don't always work the way you might think. You can actually get a block compressed down by quite a bit, and that throws all this off. You're more likely to get compression with a larger block. So the generalized answer to your query is to use a larger volblocksize and turn on compression.
This isn't the trite problem that you'd like to think it is. And I've probably made some mistakes because I'm only at two coffees this morning.
None of this helps with reads, of course, which over time become highly fragmented. ZFS typically mitigates this with gobs of ARC and L2ARC, which allow it to serve up the most frequently accessed data from the cache.
RAIDZ (including Z2, Z3) is good for storing large sequential files. ZFS will allocate long, contiguous stretches of disk for large blocks of data, compressing them, and storing the parity in an efficient manner. RAIDZ makes very good use of the raw disk space available when you are using it in this fashion. However, RAIDZ is not good at storing small blocks of data. To illustrate what I mean, consider the case where you wish to store an 8K block of data on RAIDZ3. In order to store that, you store the 8K data block, then three additional parity blocks... not efficient. Further, from an IOPS perspective, a RAIDZ vdev tends to exhibit the IOPS behaviour of a single component disk (and the slowest one, at that).
So we see a lot of people coming into the forums trying to store VM data on their 12 disk wide RAIDZ2 and wonder why their 12 disk 30 TB array sucks for performance. It's exhibiting the speed of a single disk.
The solution to this is mirrors. Mirrors aren't as good at making good use of the raw disk space (because you only end up with 1/2 or 1/3 the space), but in return for the greater resource commitment, you get much better performance. First, mirrors do not consume a variable amount of space for parity. Second, you're likely to have more vdevs. That 12 drive system we were just talking about will have 4 three-way mirrors or 6 two-way mirrors, which is 4x or 6x the number of vdevs. This translates directly to greatly enhanced performance!
Another substantial performance enhancement with ZFS is to maintain low pool occupancy rates.
For RAIDZ style file storage, it's commonly thought that performance will suffer once you pass the 80% mark, but this isn't quite right. It's a combination of fragmentation and occupancy that causes performance to suffer.
For mirrors, this is also true, but because the data being stored is often VM disk files or database files, it becomes more complicated. Because it is a copy-on-write filesystem, rewriting a block in a VM disk file causes a new block somewhere else to be allocated, and creates a hole where the old block was, when that block is freed (after any snapshots are released, etc). When writing new data, ZFS likes to allocate contiguous regions of disk to write its transaction groups. An interesting side effect of this is that if you are rewriting VM disk blocks 1, 5000, 22222, and 876543, these may actually be written as sequentially allocated blocks when ZFS dumps that transaction group to disk. A normal disk array would have to do four seeks to do those writes, but ZFS *may* be able to write them sequentially. Taken to its logical conclusion, when ZFS has massive amounts of free space available to work with, it can potentially be five or ten times faster at performing writes than a conventional disk array. The downside? ZFS will suffer if it lacks that free space.
If you want really fast VM writes, keep your occupancy rates low. As low as 10-25% if possible. Going past 50% may eventually lead to very poor performance as fragmentation grows with age and rewrites.
A discussion of how ZFS RAIDZ space allocation often chews up more space than you are expecting.
You shouldn't be using RAIDZ with block storage at all, because RAIDZ uses a variable amount of parity to protect your data depending on the block size, and this can cause excessive waste. It is totally possible to engineer a situation where your parity uses several times as much space as the data it is protecting. Performance will slowly degrade over time if your pool is more than 50% full, as well.
https://extranet.www.sol.net/files/freenas/fragmentation/delphix-small.png
[from a discussion where the poster had an 8-wide RAIDZ2] Because you've got an 8-wide Z2, your optimal block size is six drives wide.
https://extranet.www.sol.net/files/freenas/fragmentation/RAIDZ-small.png
The only case where allocation happens optimally is where you have a block size of 6 * your sector size, or some multiple thereof. So if your ashift=9, then that's a 3072 byte block, or if ashift=12, then 24576 bytes. These are not natural sizes. You only get the natural sizes if you follow the old power rules for the number of disks in a pool (RAIDZ2 = 6 or 10 disks, etc).
So then as an example of how this goes awry, if your ashift=9 and you have a zvol volblocksize of 4K, you need to allocate an (optimal) 3072 byte block on eight sectors, but then you have a leftover of two 512-byte sectors, which needs to be protected by parity, so that's three sectors, but ZFS won't allocate odd numbers, so that's four sectors, so you're using twelve total sectors to write that 4K block, or 50% overhead. If your ashift=9 and a zvol of 8K, that's two optimal blocks on sixteen sectors with a leftover of four 512-byte sectors, plus parity/pad, six more sectors, so that's twenty two sectors to write that 8K block, or 38% overhead.
But it all goes to total heck with ashift=12 (4K sectors). The most obvious one is where you have a 4K zvol volblocksize and you store a 4K block. You need a 4K parity to protect that, so you're instantly at 100% overhead. If you do that on RAIDZ3, then you actually need 3 * 4K parity to protect it, so 300% overhead. So you go to larger volblocksize. So the 8K zvol volblocksize seems like it might work out better, but in reality you need two sectors for data, one for parity, and then one for pad, so you're still at the 100% overhead. You actually have to get up into larger volblocksizes and design them in concert with your pool in order to have a chance at a more optimal configuration. As you raise the volblocksize, you will approach a more optimal situation, but not actually reach it.
But even then, this is sort of screwed up because with the introduction of ZFS compression, things don't always work the way you might think. You can actually get a block compressed down by quite a bit, and that throws all this off. You're more likely to get compression with a larger block. So the generalized answer to your query is to use a larger volblocksize and turn on compression.
This isn't the trite problem that you'd like to think it is. And I've probably made some mistakes because I'm only at two coffees this morning.
None of this helps with reads, of course, which over time become highly fragmented. ZFS typically mitigates this with gobs of ARC and L2ARC, which allow it to serve up the most frequently accessed data from the cache.