Hello everyone!
I'm a relative n00b to FreeNAS and am also quite new to FreeBSD. I just built a dedicated 6-bay FreeNAS box that I hope to be able to use in production for some of my clients. Currently, I'm doing everything I can to break RAIDz arrays and discovering the best possible procedures for recovering them so that I can document everything. I'm only a couple of days into playing with ZFS, so please bear with me if what I'm doing is totally wrong.
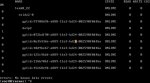
One such scenario that I have been testing is a very basic one - whereby, for example, a SATA cable is accidentally unplugged from a drive and this leads to a disk falling out of the array. Obviously, in a case like this the hard drive itself is okay and can safely be re-added to the array. Problem is, if I try to replace a drive in-place in the GUI on the "Volume Status" screen, I get the following error:
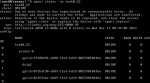
Okay, I figure the disk is marked as offline so I'm not sure why this happens. Jumping into the shell and trying a basic replace command yields the same results:
Alrighty then, lets try destroying all the GEOM labels. Surely then it could not possibly be seen as being part of the array, so I tried running:
Now I go back to the GUI and try to run a replace, but guess what? Exact same error as above. I find this quite strange so I jump back into the shell and try running the replace again, this time manually:
Lo and behold, this works! Great, but there is one last problem - in the GUI the drive no longer shows up as ada0p2 but rather ada0. This is of course because FreeNAS did not get a chance to format the drive on its own and I allowed the zpool command to do this for me.
I have found a workaround to fix this as well, but it isn't so pretty. I then have to gpart destroy ada0 yet again. Then at that point, I can replace it through the GUI and everything runs smoothly. I don't like this very much though because in a real situation, this actually means that to get FreeNAS to partition the drive on its own, I need to resilver the whole array twice. Very not cool.
Questions:
A) Surely, there is a way to avoid this. I don't mind doing everything through the shell, provided that the manual procedure is doing everything "right"
B) Could it possibly be due to the fact that FreeNAS is not handling 4k disks properly? All disks in this array are 3TB 4k advanced format drives
Thanks so much for reading, and hopefully somebody who knows way more than I about dealing with FreeBSD/ZFS/RAIDz can chime in!
I'm a relative n00b to FreeNAS and am also quite new to FreeBSD. I just built a dedicated 6-bay FreeNAS box that I hope to be able to use in production for some of my clients. Currently, I'm doing everything I can to break RAIDz arrays and discovering the best possible procedures for recovering them so that I can document everything. I'm only a couple of days into playing with ZFS, so please bear with me if what I'm doing is totally wrong.
One such scenario that I have been testing is a very basic one - whereby, for example, a SATA cable is accidentally unplugged from a drive and this leads to a disk falling out of the array. Obviously, in a case like this the hard drive itself is okay and can safely be re-added to the array. Problem is, if I try to replace a drive in-place in the GUI on the "Volume Status" screen, I get the following error:
Error: Disk replacement failed: "invalid vdev specification, use '-f' to override the following errors:, /dev/gptid/f5c99782-74ac-11e2-9834-50465d51d5dd is part of active pool 'pool', "
Okay, I figure the disk is marked as offline so I'm not sure why this happens. Jumping into the shell and trying a basic replace command yields the same results:
zpool replace pool ada0
Alrighty then, lets try destroying all the GEOM labels. Surely then it could not possibly be seen as being part of the array, so I tried running:
gpart destroy -F ada0
Now I go back to the GUI and try to run a replace, but guess what? Exact same error as above. I find this quite strange so I jump back into the shell and try running the replace again, this time manually:
zpool replace pool 1234567890123456789 ada0
Lo and behold, this works! Great, but there is one last problem - in the GUI the drive no longer shows up as ada0p2 but rather ada0. This is of course because FreeNAS did not get a chance to format the drive on its own and I allowed the zpool command to do this for me.
I have found a workaround to fix this as well, but it isn't so pretty. I then have to gpart destroy ada0 yet again. Then at that point, I can replace it through the GUI and everything runs smoothly. I don't like this very much though because in a real situation, this actually means that to get FreeNAS to partition the drive on its own, I need to resilver the whole array twice. Very not cool.
Questions:
A) Surely, there is a way to avoid this. I don't mind doing everything through the shell, provided that the manual procedure is doing everything "right"
B) Could it possibly be due to the fact that FreeNAS is not handling 4k disks properly? All disks in this array are 3TB 4k advanced format drives
Thanks so much for reading, and hopefully somebody who knows way more than I about dealing with FreeBSD/ZFS/RAIDz can chime in!