Hi all - new storage server build (my first on TrueNAS):
- Xeon 2697v3 w/ 128 GB of ECC RAM
- LSI9300-8i in IT mode
- 8x Seagate Exos x18 SAS 18TB disks
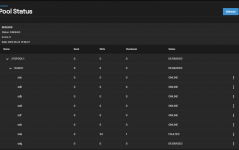
I set up as a raidz1. After it built the pool and I created a share and started transferring data to the drive I got a few error messages:



I shut the server down, replugged the SAS cables from the backplane, reseated everything, and on reboot let it run (for a number of hours) while it did its checking. It came up in the same state. Everything seems to work, but obviously this isn‘t an acceptable status to operate the pool in.
The reason I’m writing… when I check smart status, etc for /dev/sda and /dev/sdg there don’t seem to be any issues seen that would result in the FAULTED or DEGRADED status that are shown…. Anyone have ideas or should I just RMA these (new) disks immediately?
(For completeness - output of smartctl -a /dev/sda (the FAULTED drive):
root@truenas[~]# smartctl -a /dev/sda
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.109+truenas] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: SEAGATE
Product: ST18000NM004J
Revision: E002
Compliance: SPC-5
User Capacity: 18,000,207,937,536 bytes [18.0 TB]
Logical block size: 512 bytes
Physical block size: 4096 bytes
LU is fully provisioned
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Logical Unit id: 0x5000c500d82c2eff
Serial number: ZR55LD3A0000C2112BX2
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Tue May 24 19:47:57 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Grown defects during certification <not available>
Total blocks reassigned during format <not available>
Total new blocks reassigned <not available>
Power on minutes since format <not available>
Current Drive Temperature: 35 C
Drive Trip Temperature: 60 C
Accumulated power on time, hours:minutes 93:24
Manufactured in week 44 of year 2021
Specified cycle count over device lifetime: 50000
Accumulated start-stop cycles: 5
Specified load-unload count over device lifetime: 600000
Accumulated load-unload cycles: 1101
Elements in grown defect list: 0
Vendor (Seagate Cache) information
Blocks sent to initiator = 16535704
Blocks received from initiator = 770435104
Blocks read from cache and sent to initiator = 763295
Number of read and write commands whose size <= segment size = 146463
Number of read and write commands whose size > segment size = 2033
Vendor (Seagate/Hitachi) factory information
number of hours powered up = 93.40
number of minutes until next internal SMART test = 10
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 0 0 0 0 8.466 0
write: 0 0 0 0 0 394.645 0
Non-medium error count: 0
[GLTSD (Global Logging Target Save Disable) set. Enable Save with '-S on']
SMART Self-test log
Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
Description number (hours)
# 1 Background short Completed - 73 - [- - -]
# 2 Background short Completed - 49 - [- - -]
# 3 Background short Completed - 25 - [- - -]
# 4 Background short Completed - 4 - [- - -]
Long (extended) Self-test duration: 65535 seconds [1092.2 minutes]
root@truenas[~]#
- Xeon 2697v3 w/ 128 GB of ECC RAM
- LSI9300-8i in IT mode
- 8x Seagate Exos x18 SAS 18TB disks
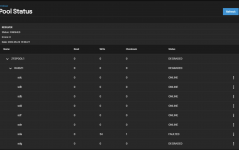
I set up as a raidz1. After it built the pool and I created a share and started transferring data to the drive I got a few error messages:
I shut the server down, replugged the SAS cables from the backplane, reseated everything, and on reboot let it run (for a number of hours) while it did its checking. It came up in the same state. Everything seems to work, but obviously this isn‘t an acceptable status to operate the pool in.
The reason I’m writing… when I check smart status, etc for /dev/sda and /dev/sdg there don’t seem to be any issues seen that would result in the FAULTED or DEGRADED status that are shown…. Anyone have ideas or should I just RMA these (new) disks immediately?
(For completeness - output of smartctl -a /dev/sda (the FAULTED drive):
root@truenas[~]# smartctl -a /dev/sda
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.109+truenas] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: SEAGATE
Product: ST18000NM004J
Revision: E002
Compliance: SPC-5
User Capacity: 18,000,207,937,536 bytes [18.0 TB]
Logical block size: 512 bytes
Physical block size: 4096 bytes
LU is fully provisioned
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Logical Unit id: 0x5000c500d82c2eff
Serial number: ZR55LD3A0000C2112BX2
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Tue May 24 19:47:57 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Grown defects during certification <not available>
Total blocks reassigned during format <not available>
Total new blocks reassigned <not available>
Power on minutes since format <not available>
Current Drive Temperature: 35 C
Drive Trip Temperature: 60 C
Accumulated power on time, hours:minutes 93:24
Manufactured in week 44 of year 2021
Specified cycle count over device lifetime: 50000
Accumulated start-stop cycles: 5
Specified load-unload count over device lifetime: 600000
Accumulated load-unload cycles: 1101
Elements in grown defect list: 0
Vendor (Seagate Cache) information
Blocks sent to initiator = 16535704
Blocks received from initiator = 770435104
Blocks read from cache and sent to initiator = 763295
Number of read and write commands whose size <= segment size = 146463
Number of read and write commands whose size > segment size = 2033
Vendor (Seagate/Hitachi) factory information
number of hours powered up = 93.40
number of minutes until next internal SMART test = 10
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 0 0 0 0 8.466 0
write: 0 0 0 0 0 394.645 0
Non-medium error count: 0
[GLTSD (Global Logging Target Save Disable) set. Enable Save with '-S on']
SMART Self-test log
Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
Description number (hours)
# 1 Background short Completed - 73 - [- - -]
# 2 Background short Completed - 49 - [- - -]
# 3 Background short Completed - 25 - [- - -]
# 4 Background short Completed - 4 - [- - -]
Long (extended) Self-test duration: 65535 seconds [1092.2 minutes]
root@truenas[~]#