
Hi
I'm having a strange problem. I get a kernel panic during boot when trying to mount the filesystem. This started two days ago when I heard the system reboot. I got an email alerting me to the fact that the pool was online but that a device had experienced an error which could result in data corruption. I ran zpool status and smarctl on each device to see what was going on (see below)
smartctl output
I restarted the system, but the system refused to boot and there were a lot of errors the details of which escape me now. I then ran memtest which refused to boot, so I removed all the RAM on a hunch, and then ran memtest on each stick of RAM individually. As it turns out, apparently one stick was causing the problem and, after removing the offending stick of ram, I was able to run memtest overnight on the remaining 3 sticks (4 or 5 passes, no errors).
I then unplugged all the hard drives and booted the system. It started without issue.
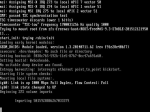
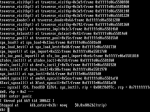
Satisfied (and hoping the problem was resolved) I plugged them all back in and restarted the computer. It managed to get all the way up to when it tried to mount the zfs pool. I got a nasty kernal panic message and a lot of text (I feel like there was probably more than this, but the frames of the capture didn't get anything more):


I'm at a loss for where to go now. I feel like I need to try and mount the zfs pool in read-only mode and scrub it, or something. I don't really hold high hopes for the data at this point, but I'd love to restore it if at all possible. Any help at all would be greatly appreciated. Let me know if I can provide any other information at this point
System:
FreeNAS-9.3-STABLE-201512121950 64 bit of a SanDisk 8GB USB drive
Motherboard: Supermicro X10-SL7-F
CPU: Intel XEON E3-1231v3
RAM: 4x8GB Crucial ECC RAM (CT2CP102472BD160B)
HDD: 6x3TB WD Red in Raidz2 configuration (WD30EFRX)
Boot device is a Sandisk 8GB USB drive
On creation of the system, memtest ran without fault overnight.
I'm having a strange problem. I get a kernel panic during boot when trying to mount the filesystem. This started two days ago when I heard the system reboot. I got an email alerting me to the fact that the pool was online but that a device had experienced an error which could result in data corruption. I ran zpool status and smarctl on each device to see what was going on (see below)
Code:
[root@freenas] /var/log# zpool status -v
pool: freenas-boot
state: ONLINE
scan: scrub repaired 0 in 0h2m with 0 errors on Tue Dec 29 03:47:35 2015
config:
NAME STATE READ WRITE CKSUM
freenas-boot ONLINE 0 0 0
gptid/24e9b3bd-592b-11e5-bcc2-0cc47a691a60 ONLINE 0 0 0
errors: No known data errors
pool: volume1
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: http://illumos.org/msg/ZFS-8000-8A
scan: scrub repaired 0 in 3h54m with 0 errors on Sun Nov 29 03:54:51 2015
config:
NAME STATE READ WRITE CKSUM
volume1 ONLINE 0 0 22
raidz2-0 ONLINE 0 0 44
gptid/7727335e-58ec-11e5-95ec-0cc47a691a60 ONLINE 0 0 0
gptid/77d24c41-58ec-11e5-95ec-0cc47a691a60 ONLINE 0 0 0
gptid/787d3011-58ec-11e5-95ec-0cc47a691a60 ONLINE 0 0 0
gptid/792f59c3-58ec-11e5-95ec-0cc47a691a60 ONLINE 0 0 0
gptid/79da0661-58ec-11e5-95ec-0cc47a691a60 ONLINE 0 0 0
gptid/7a825715-58ec-11e5-95ec-0cc47a691a60 ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
/mnt/volume1/jails/maraschino_1/etc/spwd.db
smartctl output
I restarted the system, but the system refused to boot and there were a lot of errors the details of which escape me now. I then ran memtest which refused to boot, so I removed all the RAM on a hunch, and then ran memtest on each stick of RAM individually. As it turns out, apparently one stick was causing the problem and, after removing the offending stick of ram, I was able to run memtest overnight on the remaining 3 sticks (4 or 5 passes, no errors).
I then unplugged all the hard drives and booted the system. It started without issue.
Satisfied (and hoping the problem was resolved) I plugged them all back in and restarted the computer. It managed to get all the way up to when it tried to mount the zfs pool. I got a nasty kernal panic message and a lot of text (I feel like there was probably more than this, but the frames of the capture didn't get anything more):
I'm at a loss for where to go now. I feel like I need to try and mount the zfs pool in read-only mode and scrub it, or something. I don't really hold high hopes for the data at this point, but I'd love to restore it if at all possible. Any help at all would be greatly appreciated. Let me know if I can provide any other information at this point
System:
FreeNAS-9.3-STABLE-201512121950 64 bit of a SanDisk 8GB USB drive
Motherboard: Supermicro X10-SL7-F
CPU: Intel XEON E3-1231v3
RAM: 4x8GB Crucial ECC RAM (CT2CP102472BD160B)
HDD: 6x3TB WD Red in Raidz2 configuration (WD30EFRX)
Boot device is a Sandisk 8GB USB drive
On creation of the system, memtest ran without fault overnight.
Attachments
Last edited:

![2015-12-31 10_29_34-Java iKVM Viewer v1.69 r13 [10.0.0.33] - Resolution 720 X 400 - FPS 32.png](/community/data/attachments/9/9352-c4ebd3db0c07ebae87a76a3c66e97184.jpg)