MhaynesVCI
Cadet
- Joined
- Jun 25, 2013
- Messages
- 4
Hi!
So we're in the process of deploying a FreeNAS for VMware iSCSI commodity storage. As a part of my PoC I was benchmarking the system to see what kind of results we could expect. I used iometer and the test template found in the Unofficial VMWare Storage Performance Thread (http://communities.vmware.com/thread/197844?start=0&tstart=0)
During my testing my results for the random 8K tests dropped drastically (from 10K+ iops to 100-200). I was messing around with some advanced iSCSI settings, which triggered an iSCSI service restart and magically all the tests started to return good results again.
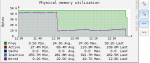
I took a look at the system resource reporting and noticed the "wired bytes" memory value dropped drastically after the iSCSI restart (screenshot attached). And, as I continue to test, it's raising again and will likely cause the same problem if unresolved.
Now, I assume this has been caused by me inadvertently enabling either compression or de-dup on the ZFSvols I'm using as my iSCSI targets, but I can't for the life of me find out where to disable these attributes - or even verify they are indeed enabled. The root volume (mnt/vol1) I used to create them has it's compression set to "inherit" (from where I don't know) and it's de-dup disabled. If I edit the source volume, will that propagate down to the ZFSvols? I also assume I want to disable atime for performance increases. I'm hoping I don't need to re-create the ZFSvols to edit these values...
Any help would be appreciated. Thanks!
So we're in the process of deploying a FreeNAS for VMware iSCSI commodity storage. As a part of my PoC I was benchmarking the system to see what kind of results we could expect. I used iometer and the test template found in the Unofficial VMWare Storage Performance Thread (http://communities.vmware.com/thread/197844?start=0&tstart=0)
During my testing my results for the random 8K tests dropped drastically (from 10K+ iops to 100-200). I was messing around with some advanced iSCSI settings, which triggered an iSCSI service restart and magically all the tests started to return good results again.
I took a look at the system resource reporting and noticed the "wired bytes" memory value dropped drastically after the iSCSI restart (screenshot attached). And, as I continue to test, it's raising again and will likely cause the same problem if unresolved.
Now, I assume this has been caused by me inadvertently enabling either compression or de-dup on the ZFSvols I'm using as my iSCSI targets, but I can't for the life of me find out where to disable these attributes - or even verify they are indeed enabled. The root volume (mnt/vol1) I used to create them has it's compression set to "inherit" (from where I don't know) and it's de-dup disabled. If I edit the source volume, will that propagate down to the ZFSvols? I also assume I want to disable atime for performance increases. I'm hoping I don't need to re-create the ZFSvols to edit these values...
Any help would be appreciated. Thanks!