scurrier
Patron
- Joined
- Jan 2, 2014
- Messages
- 297
While installing a new network switch today I accidentally created a loop. In the other room I hear my FreeNAS box reboot and it took me a moment to figure out what was going on. It might have rebooted more than once. So I fix the problem and then get into FreeNAS and what joys await me:

My volume "firstvol" is unavailable. I don't know what to do so for now I shut down the machine. Looking for any advice. I have a backup- replicating the important stuff on firstvol to a second ZFS volume, but not all of it. Hopefully that second volume is OK. I did have a third backup, but I keep it at work and so it is not as updated with pictures of my son, etc. I still hope to recover the un-backed-up stuff from firstvol if anyone can help me do it.
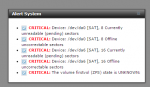
Full disclosure, da6 caused an email to me earlier today for its issues in this screenshot, seemingly unrelated to the network loop incident. da6 is not a part of firstvol though and wasn't even being used so I didn't worry about it right away. da0 is a part of firstvol so I am worried about it. It looks like all my disks still appear in the GUI "view disks".
Funny thing is, I never have caused a network loop in all my years of networking. Then, I buy my first smart switch which has features to prevent loops, but they don't come default enabled and then I go and cause a loop when I first plug it in. And then my monster FreeNAS box crashes and a volume gets damaged. Figures.
I didn't even know a broadcast storm could cause a machine to reboot. I guess experience really is what you get when you don't get what you want.
Any reason not to turn this machine back on and see if it magically sorts out its problems?
My volume "firstvol" is unavailable. I don't know what to do so for now I shut down the machine. Looking for any advice. I have a backup- replicating the important stuff on firstvol to a second ZFS volume, but not all of it. Hopefully that second volume is OK. I did have a third backup, but I keep it at work and so it is not as updated with pictures of my son, etc. I still hope to recover the un-backed-up stuff from firstvol if anyone can help me do it.
Full disclosure, da6 caused an email to me earlier today for its issues in this screenshot, seemingly unrelated to the network loop incident. da6 is not a part of firstvol though and wasn't even being used so I didn't worry about it right away. da0 is a part of firstvol so I am worried about it. It looks like all my disks still appear in the GUI "view disks".
Funny thing is, I never have caused a network loop in all my years of networking. Then, I buy my first smart switch which has features to prevent loops, but they don't come default enabled and then I go and cause a loop when I first plug it in. And then my monster FreeNAS box crashes and a volume gets damaged. Figures.
I didn't even know a broadcast storm could cause a machine to reboot. I guess experience really is what you get when you don't get what you want.
Any reason not to turn this machine back on and see if it magically sorts out its problems?