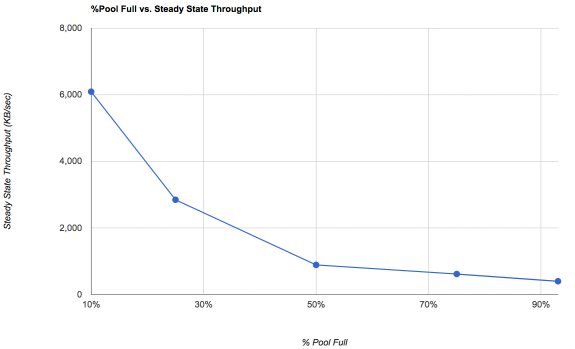
Well, it's helpful to be real clear on what you're seeing here. This is the ability of the pool to sustain a given level of random throughput at a particular occupancy level. This is pretty much "worst case behaviour" and not what you should actually expect, unless you're running databases or virtual machines and doing lots of writes, and you've been doing it long enough for things to reach a steady state.
What's more important is what the chart implies.
For a random I/O workload on a standard hard disk, let's say capable of 100 IOPS, 4K times 100 IOPS is only 400KB/sec. Because ZFS is taking random writes and aggregating them into a transaction group, that translates to FIFTEEN TIMES FASTER at 10% occupancy - the ZFS device can sustain what appears to the application to be 1500 IOPS or 6000KB/sec. As you fill the pool, it falls down towards the number of IOPS the underlying disk can support, because fundamentally if it can't aggregate into sequential writes then it has to seek for small blocks.
The other easily-missed thing here is that this also applies to sequential writes. Once there's a huge amount of fragmentation on the pool, even what we'd normally think of as sequential writes are also slowed down, which might really tick you off if you're used to your hard drive pulling 200MB/sec write speeds and suddenly you're getting 1MB/sec because your pool is fairly full and fairly fragmented.
If a light bulb goes off in your head and you suddenly realize that ZFS write speeds aren't really expected to be substantially different for random vs sequential speeds, ... good. It's all tied closely to fragmentation and pool occupancy. Not randomness of the workload, at least not all that much.
Reads, on the other hand, that's another matter. The biggest thing is that the tendency of a CoW filesystem like ZFS to deposit data wherever is convenient means that things we might expect to be sequential (large files, VM disk files) might or might not be. If I lay down an ISO on a relatively empty pool and never touch it, obviously it remains generally sequential. A VM disk file will also be laid down sequentially, but every update will involve shuffled blocks. That's where the ARC and the L2ARC can come in to help win the day. Your big VM disk file may be as scrambled up as the pieces of a puzzle still unassembled in a box.
Memory prices have now fallen to the point where 128GB of RAM is only ~$800, and a pair of competent NVMe L2ARC devices is about ~$700, so for $1500 you can outfit ZFS with a terabyte of cache on a Xeon E5. This will make sense for some people to do.