DarkSideMilk
Dabbler
- Joined
- Feb 22, 2019
- Messages
- 13
Freenas server info:
Motherboard: Supermicro PDSM4+
RAM: 8GB
CPU: Intel Xeon X3220 (4 cores)
Freenas OS Drive: Samsung Sata SSD 860 PRO 256 GB
Storage Controller: 3ware 12 Drive sata raid controller (9650SE SATA-II RAID PCIe)
Storage Config: 3x4 (3 pools with 4 drives per pool) RaidZ2. 12 1.5 TB Drives ~10TB in the pool
Network: 2 x Intel 82573E Gigabit Ethernet. Only 1 currently configured.
FreeNas Version: FreeNAS-11.3-U1 (The pool has been upgraded to the latest version with this upgrade)
The Problem:
In the last month or so, probably a little after we upgraded to FreeNas 11.3 (may be related, hoping it's not) we started needing to go manually reset our freenas server.
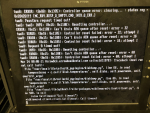
We would come in some morning and find that we couldn't mount the server or some other related function and go investigate to find the a server unresponsive to keystrokes with the following errors on the console screen

I searched the forums for related errors and haven't found anything. Hoping that someone can help.
It appears that something is going wrong during the verify of the 3ware controller drives. I'm hoping there's something I can do to fix this and that the controller isn't just dying.
We're not entirely sure when this is happening or exactly how often, but we've had to manually reset once every 1-2 weeks for the last month. We updated to 11.3 U1 on the 2/28 hoping that the issue would be fixed in the update, but sadly it has returned about a week and a half later.
Thanks in advnance!
-JJ
Motherboard: Supermicro PDSM4+
RAM: 8GB
CPU: Intel Xeon X3220 (4 cores)
Freenas OS Drive: Samsung Sata SSD 860 PRO 256 GB
Storage Controller: 3ware 12 Drive sata raid controller (9650SE SATA-II RAID PCIe)
Storage Config: 3x4 (3 pools with 4 drives per pool) RaidZ2. 12 1.5 TB Drives ~10TB in the pool
Network: 2 x Intel 82573E Gigabit Ethernet. Only 1 currently configured.
FreeNas Version: FreeNAS-11.3-U1 (The pool has been upgraded to the latest version with this upgrade)
The Problem:
In the last month or so, probably a little after we upgraded to FreeNas 11.3 (may be related, hoping it's not) we started needing to go manually reset our freenas server.
We would come in some morning and find that we couldn't mount the server or some other related function and go investigate to find the a server unresponsive to keystrokes with the following errors on the console screen
I searched the forums for related errors and haven't found anything. Hoping that someone can help.
It appears that something is going wrong during the verify of the 3ware controller drives. I'm hoping there's something I can do to fix this and that the controller isn't just dying.
We're not entirely sure when this is happening or exactly how often, but we've had to manually reset once every 1-2 weeks for the last month. We updated to 11.3 U1 on the 2/28 hoping that the issue would be fixed in the update, but sadly it has returned about a week and a half later.
Thanks in advnance!
-JJ