Hi Guys.
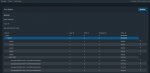
I'm having a storage issue following a Degraded State warning. I took the offending disk offline, replaced it, formatted t, put it online and let it resilver. I have done this three times now with different disks and each time after the resilvering has finished the status shows Degrade and when I look at the pool it shows as per the attached images.
I also can't detach the disks as I get the error:
Error: concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 247, in __zfs_vdev_operation
op(target, *args)
File "libzfs.pyx", line 369, in libzfs.ZFS.__exit__
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 247, in __zfs_vdev_operation
op(target, *args)
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 256, in <lambda>
self.__zfs_vdev_operation(name, label, lambda target: target.detach())
File "libzfs.pyx", line 1764, in libzfs.ZFSVdev.detach
libzfs.ZFSException: Can detach disks from mirrors and spares only
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/concurrent/futures/process.py", line 239, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 97, in main_worker
res = loop.run_until_complete(coro)
File "/usr/local/lib/python3.7/asyncio/base_events.py", line 579, in run_until_complete
return future.result()
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 53, in _run
return await self._call(name, serviceobj, methodobj, params=args, job=job)
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 45, in _call
return methodobj(*params)
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 45, in _call
return methodobj(*params)
File "/usr/local/lib/python3.7/site-packages/middlewared/schema.py", line 965, in nf
return f(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 256, in detach
self.__zfs_vdev_operation(name, label, lambda target: target.detach())
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 249, in __zfs_vdev_operation
raise CallError(str(e), e.code)
middlewared.service_exception.CallError: [EZFS_NOTSUP] Can detach disks from mirrors and spares only
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 130, in call_method
io_thread=False)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1084, in _call
return await methodobj(*args)
File "/usr/local/lib/python3.7/site-packages/middlewared/schema.py", line 961, in nf
return await f(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/pool.py", line 1195, in detach
await self.middleware.call('zfs.pool.detach', pool['name'], found[1]['guid'])
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1141, in call
app=app, pipes=pipes, job_on_progress_cb=job_on_progress_cb, io_thread=True,
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1081, in _call
return await self._call_worker(name, *args)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1101, in _call_worker
return await self.run_in_proc(main_worker, name, args, job)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1036, in run_in_proc
return await self.run_in_executor(self.__procpool, method, *args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1010, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
middlewared.service_exception.CallError: [EZFS_NOTSUP] Can detach disks from mirrors and spares only
I'm by no means an expert with FreeNAS, and I'm sure the disks I am using are as replacements are fine, but I can't see why I can't just replace this disk and add it into the pool.
Appreciate any assistance.
Cheers,
Woz.
I'm having a storage issue following a Degraded State warning. I took the offending disk offline, replaced it, formatted t, put it online and let it resilver. I have done this three times now with different disks and each time after the resilvering has finished the status shows Degrade and when I look at the pool it shows as per the attached images.
I also can't detach the disks as I get the error:
Error: concurrent.futures.process._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 247, in __zfs_vdev_operation
op(target, *args)
File "libzfs.pyx", line 369, in libzfs.ZFS.__exit__
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 247, in __zfs_vdev_operation
op(target, *args)
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 256, in <lambda>
self.__zfs_vdev_operation(name, label, lambda target: target.detach())
File "libzfs.pyx", line 1764, in libzfs.ZFSVdev.detach
libzfs.ZFSException: Can detach disks from mirrors and spares only
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/concurrent/futures/process.py", line 239, in _process_worker
r = call_item.fn(*call_item.args, **call_item.kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 97, in main_worker
res = loop.run_until_complete(coro)
File "/usr/local/lib/python3.7/asyncio/base_events.py", line 579, in run_until_complete
return future.result()
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 53, in _run
return await self._call(name, serviceobj, methodobj, params=args, job=job)
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 45, in _call
return methodobj(*params)
File "/usr/local/lib/python3.7/site-packages/middlewared/worker.py", line 45, in _call
return methodobj(*params)
File "/usr/local/lib/python3.7/site-packages/middlewared/schema.py", line 965, in nf
return f(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 256, in detach
self.__zfs_vdev_operation(name, label, lambda target: target.detach())
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/zfs.py", line 249, in __zfs_vdev_operation
raise CallError(str(e), e.code)
middlewared.service_exception.CallError: [EZFS_NOTSUP] Can detach disks from mirrors and spares only
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 130, in call_method
io_thread=False)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1084, in _call
return await methodobj(*args)
File "/usr/local/lib/python3.7/site-packages/middlewared/schema.py", line 961, in nf
return await f(*args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/plugins/pool.py", line 1195, in detach
await self.middleware.call('zfs.pool.detach', pool['name'], found[1]['guid'])
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1141, in call
app=app, pipes=pipes, job_on_progress_cb=job_on_progress_cb, io_thread=True,
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1081, in _call
return await self._call_worker(name, *args)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1101, in _call_worker
return await self.run_in_proc(main_worker, name, args, job)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1036, in run_in_proc
return await self.run_in_executor(self.__procpool, method, *args, **kwargs)
File "/usr/local/lib/python3.7/site-packages/middlewared/main.py", line 1010, in run_in_executor
return await loop.run_in_executor(pool, functools.partial(method, *args, **kwargs))
middlewared.service_exception.CallError: [EZFS_NOTSUP] Can detach disks from mirrors and spares only
I'm by no means an expert with FreeNAS, and I'm sure the disks I am using are as replacements are fine, but I can't see why I can't just replace this disk and add it into the pool.
Appreciate any assistance.
Cheers,
Woz.